Conditional Generative Adversarial Nets
1. Generative Adversarial Nets
GAN由两个“对抗性”模型组成:捕获数据分布的生成模型(generative model),判别模型(discriminative model) 估计样本来自训练数据而不是 的概率。 和 两者可以是非线性映射函数,例如多层感知机。
为了学习在数据 上的生成分布 ,生成器建立了一个从先前噪声分布(prior noise distribution) 到数据空间(data space)的映射函数 。同时判别器 输出一个标量表示 来自训练数据而不是 的概率。
和 同时训练:我们调整 的参数来最小化 ,调整 的参数来最小化 ,就好像他们遵循的是带有价值函数 的双人minimax博弈:
对于判别器的输入,无论是真是样本还是预测样本,输入只有 和 。在真实的数据中,例如MNIST,照片有10类(0~9手写字识别),对于10类样本,输入仅有一个高斯变量 ,而没有输入任何其他信息,指望生成器生成相似照片难度较大。输入中真正有帮助预测照片的数据非常少,因此诞生了条件GAN。
2. Conditional Generative Adversarial Nets
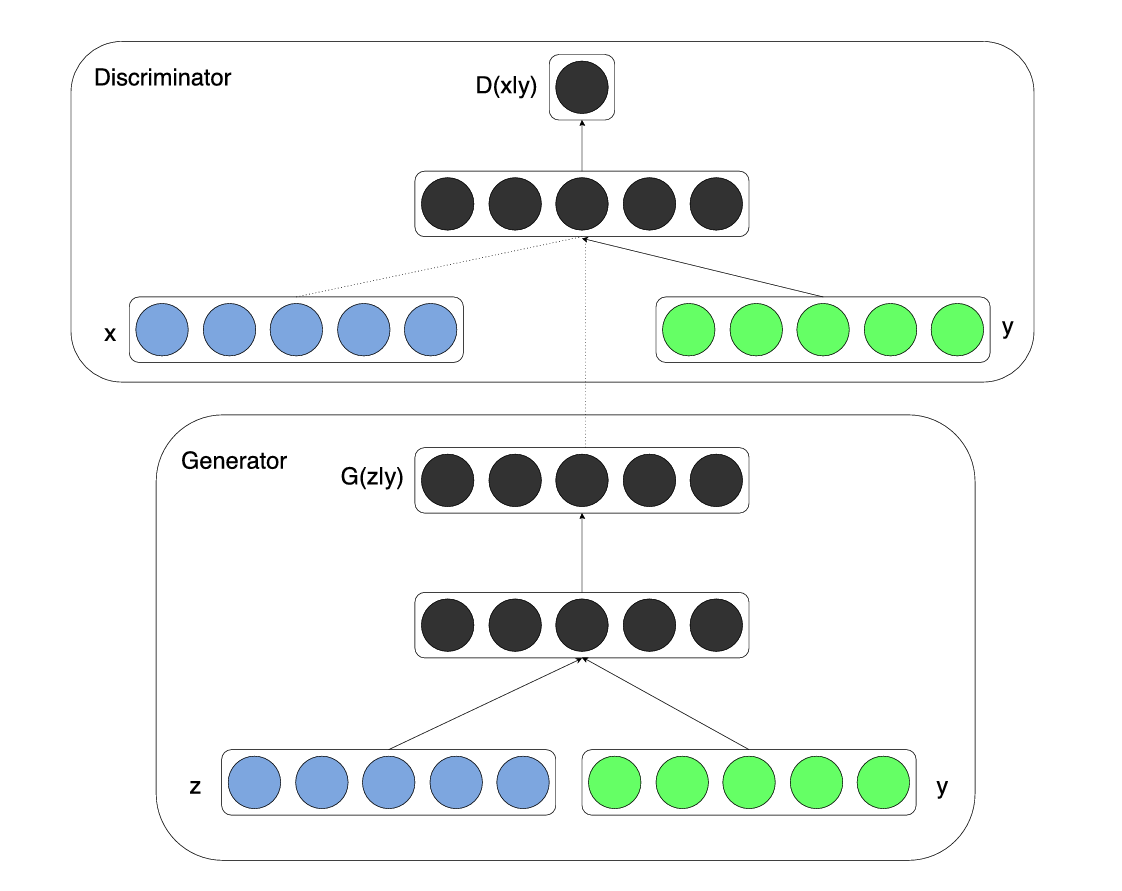
如果生成器和判别器都以一些额外的信息 为条件,那么 GAN 可以扩展到条件模型。 可以是任何类型的辅助信息,例如类标签或来自其他模态的数据。我们可以通过将 作为附加输入层同时输入鉴别器和生成器来执行调节。
在生成器中,先验输入噪声 和 被组合在联合隐藏表示中,并且对抗性训练框架允许在如何组成该隐藏表示方面具有相当大的灵活性。
在判别器中, 和 被表示为一个判别函数的输入(在本例中再次由MLP体现)。
双人minimax博弈的目标函数为:
一个简单的条件对抗网络的结构: